When you start tuning a Tableau dashboard or SQL query for performance, one thing jumps out quickly: COUNTD can slow things down.

The count-distinct is an extremely useful function which looks simple on the surface, but under the hood it forces the engine to do extra work that adds up fast. Understanding why this happens – and what alternatives you can use – makes a big difference in keeping your dashboards responsive.
Once you dig into query performance tuning, you’ll quickly learn that COUNTD can have a noticeable impact on speed. About every article on performance warns you to avoid using count distinct if you want a fast dashboard. But why is this, and what are alternatives?
Using Count Distinct
Although the function is infamous for bad performance on big datasets, it is used very often. Some examples of the many:
- Unique error codes in a logfile
- Number of orders from a table on a level of detail of articles
- Number of website visitor who did click at least once on a certain button type

Why it is slow: “Count” vs “Count Distinct”
A ‘count distinct’ returns the unique number of elements in the data, while ‘count’ return the number of elements. Let’s convert this theory into something practical example using a jar of marbles:

COUNT
“How many marbles are in the jar?”
You just pick them up one by one and count
“1, 2, 3, 4, …”
This is fast and cheap: you don’t need to memorize any marbles, no comparison, no sorting
COUNT DISTINCT
“How many different colors of marbles are in the jar?”
Now you can’t just count, you have to keep track of which colors you’ve already seen. So you take out a marble and think:
- “Red – have I seen red before?”
- “Blue – is blue already on my list?”
- “Green – new color! add it to my list.”
You keep a running list (in your head or on paper) of all the unique colors.
At the end, you count the colors on that list.
Count Distinct in databases
Similar to the marbles, a COUNT DISTINCT is hard to calculate (“expensive”) because the database (or Tableau engine) can’t just count rows. It has to first find all unique values before it can count them.
That means:
- It needs to look at every row in your dataset.
- It must remember all the distinct values it has seen so far (often by building a temporary list in memory).
- Only after finishing that full scan it knows the number of unique values.
So instead of just doing “count, count, count” (one, two, three, …) as it reads data, it’s doing
“check if we’ve seen this before → if not, add it → continue”.
That checking and storing step costs both time and memory, especially with large datasets or high-cardinality fields (many unique values, like IDs or emails).
In short:
A simple COUNT just tallies rows.
A COUNT DISTINCT has to de-duplicate first, which is a lot more work.
I still need it!
If your dashboard is slow because of count-distinct on a large dataset, you might need to look at some other solutions:
1. Skipping count distinct – do you really need it?
Before you dive into more complex solutions, start by checking your data. If you are counting something which is already unique per row, you can use a simple COUNT instead of COUNTD. It’s the easiest performance boost you’ll ever get.
2. Pre-Aggregate
The most powerful solution is to calculate the count-distinct in advance. Let the database do the hard work in advance and materialize it in the extract:
SELECT date, SUM(sales) AS total_daily_sales, COUNT(DISTINCT customer_id) AS unique_customer_count FROM transactions GROUP BY transaction_date;The biggest disadvantage is its inflexibility: counting unique number of customers by month or by country requires a new, different database query.
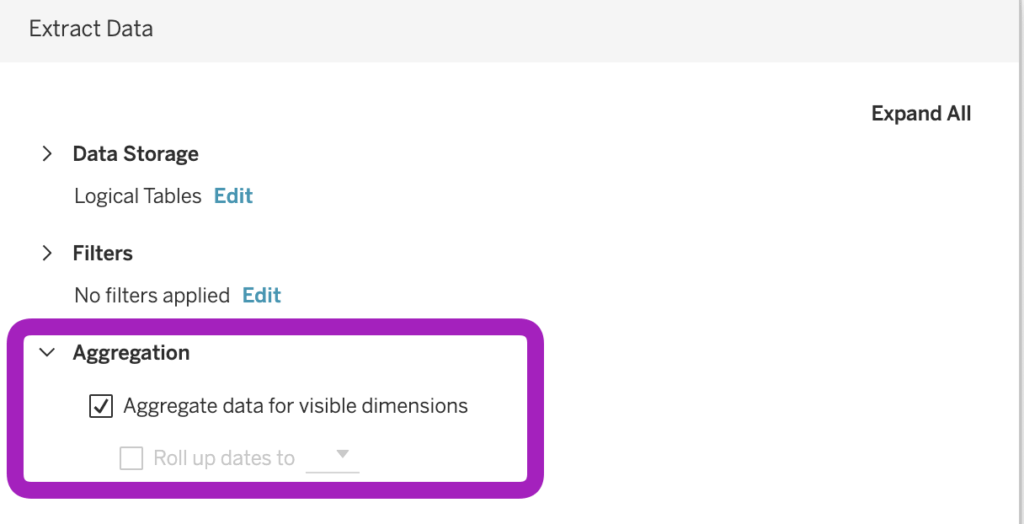
3. Aggregate the data
If you aggregate your data at the level of the dimension you want to count distinctly, a simple COUNT of the records in the extract may be equivalent to a COUNTD of the original data. You can do this in the database, but Tableau also offers this option if you create an extract:
4. Fixed Level of Detail Calculation
This one might surprise you: a Fixed LOD can make your dashboard faster. In every (good) article on Tableau performance you are warned about using Level of Detail calculations, but this can be in fact a major performance booster.
It is a two-step process, by flagging the Unique ID
{FIXED [Order ID]:MIN(1)}This creates a new ‘column’ in the dataset where every row associated with the same [Order ID] gets the value 1.
Since the aggregation (the FIXED part) is executed early in Tableau’s order of operations, and the final aggregation is a simple SUM, this method often performs much faster than a standard COUNTD.
More examples on how to use this method can be found in this article from PHData

Performance gain
In a recent dashboard (with a couple of million rows of relevant data) I was able to cut down the loading time from 7 to 4 seconds using the FIXED LOD method. The performance gain (if any) depends on many factors, like the diversity of the data (cardinality), using extract (often fast), kind of database on live connections (BigQuery, Snowflake, Redshift have some optimizations on count distinct), and of course the amount of data (less data is faster).
Conclusion
In the end, it is definitely not about avoiding COUNTD altogether, but about knowing when it helps and when it hurts. With a better understanding of how distinct counting works and when {FIXED} calculations outperform it, you can choose the right tool for the job. A small shift in approach can result in noticeably faster dashboards and more predictable performance.